Indexes
Indexes are powerful tools Datomic provides for leverage data. Datomic indexes are used behind the scenes to implement datalog query and entities, and it is possible to access directly through methods of Database and Connection.
The examples in this document use a simplified subset of the datoms in the MusicBrainz sample database.
Basics
Datomic indexes are covering indexes. This means the index actually contains the datoms, rather than just a pointer to them. When finding datoms in the index, the user gets the datoms themselves, not just a reference to where they live. This allows Datomic to very efficiently access datoms through its indexes.
Datomic maintains four indexes that contain ordered sets of datoms. Each of these indexes is named based on the sort order used. E, A, and V are always sorted in ascending order, while T is always in descending order:
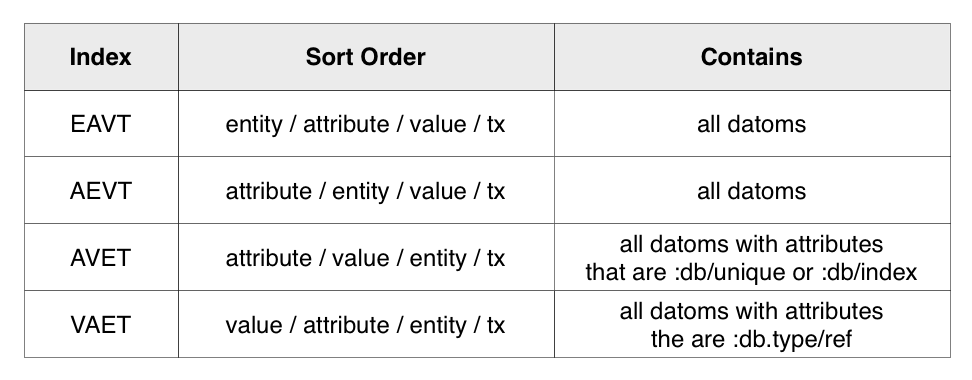
EAVT
The EAVT index provides efficient access to everything about a given entity. Conceptually this is very similar to row access style in a SQL database, except that entities can possess arbitrary attributes rather than being limited to a predefined set of columns.
The example below shows all of the facts about entity 42 grouped together:
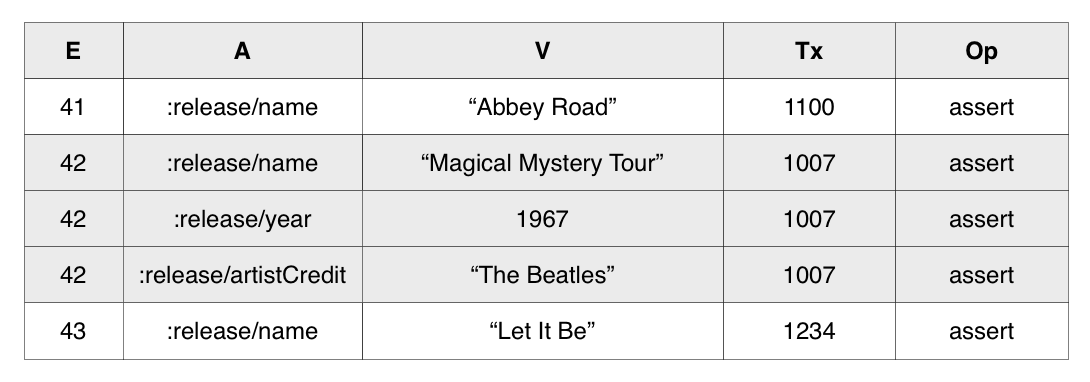
EAVT is also useful in master or detail lookups, since the references to detail entities are just ordinary versus alongside the scalar attributes of the master entity. Better still, Datomic assigns entity ids so that when master and detail records are created in the same transaction, they are colocated in EAVT.
AEVT
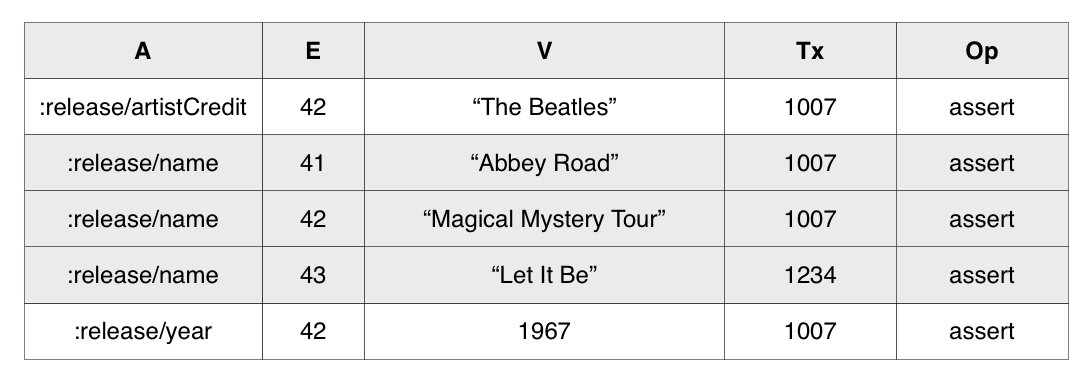
The AEVT index provides efficient access to all values for a given attribute, comparable to the traditional column access style. In the table below, notice how all :release/name attributes are grouped together. This allows Datomic to efficiently query for all values of the :release/name attribute, because they reside next to one another in this index.
AVET
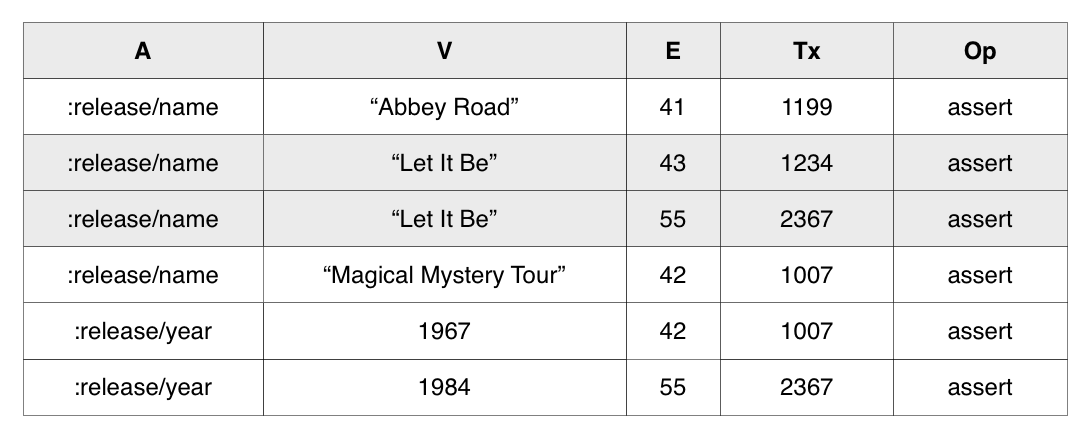
The AVET index provides efficient access to particular combinations of attribute and value. The example below shows a portion of the AVET index allowing lookup by :release/names.
The AVET index is more expensive to maintain than other indexes, and as such it is the only index that is not enabled by default. To maintain AVET for an attribute, specify :db/index true (or some value for :db/unique) when installing or altering the attribute.
The AVET index also supports the indexRange API, which returns all attribute values in a particular range.
VAET
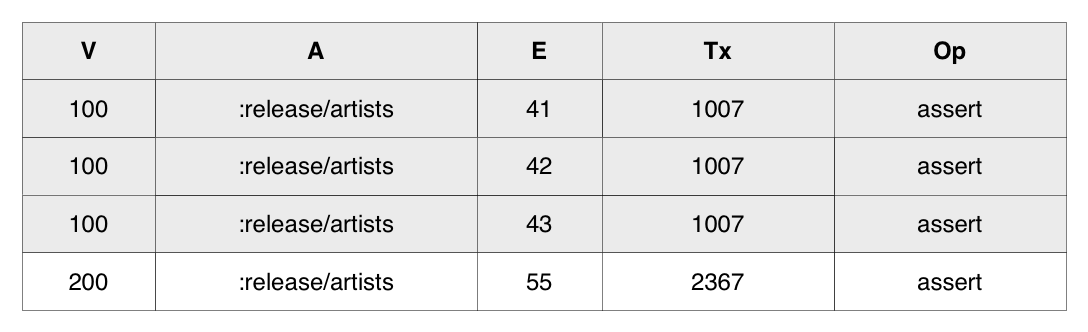
The VAET index contains all and only datoms whose attribute has a :db/valueType of :db.type/ref. This is also known as the reverse index since it allows efficient navigation of relationships in reverse. Assuming that The Beatles are entity 100, check the following table how their releases would be grouped together in this index:
Datoms API
The datoms API provides direct access to one of the datoms indexes. Given an index name, and a partial specification of a datom, datoms returns an Iterable over all the datoms matching that specification in the index.
Datom components are specified in the same order as the index. The example below refers to AVET, so the first component :account/balance specifies the A component, and returns an iterator over all balances in the system:
db.datoms(AVET, ":account/balance");
A call to datoms with no components returns the entire index. Because EAVT and AEVT include every datom in the database, either of these indexes could be used to walk the entire database:
// lazily iterate the entire database! db.datoms(EAVT);
Log
The log indexes datoms by time. The log is unlike the other indexes in several ways.
- The log is an ordered set of transactions, where each transaction itself contains an unordered set of datoms.
- The log is available as a method on Connection, not on Database.
- The log is not used automatically by query. Instead, it is accessed from within query via the query functions tx-ids and tx-data.
See the Log API document for details on using the log.
Implementation
Accumulate Only
Datomic is accumulate-only. Information accumulates over time, and change is represented by accumulating the new, not by modifying or removing the old. For example, "removing" occurs not by taking something away, but by adding a new retraction.
At the implementation level, this means that index and log segments are immutable, and can be consumed directly without coordination by any processes in a Datomic system. This is the reason that Datomic processes are called peers - all processes have equivalent access to the information in the system. In addition, because the indexes are immutable, they can be efficiently cached in application processes.
Note that accumulate-only is a semantic property, and is not the same as append-only, which is a structural property describing how data is written. Datomic is not an append-only system, and does not have the performance characteristics associated with append-only systems.
Efficient Accumulation
The Datomic API presents indexes to consumers as sorted sets of datoms or of transactions. However, Datomic is designed for efficient writing at transaction time, and for use with data sets much larger than can fit in memory. To meet these objectives, Datomic:
- Stores indexes as shallow trees of segments, where each segment typically contains thousands of datoms.
- Stores segments, not raw datoms, in storage.
- Updates the datom trees only occasionally, via background indexing jobs.
- Uses an adaptive indexing algorithm that has a sublinear relationship with total database size.
- Merges index trees with an in-memory representation of recent changes so that peers see up-to-date indexes.
- Updates the log for every transaction (the D in ACID)
- Optimizes log writes using additional data structures tuned to allow O(1) storage writes per transaction.
Efficient Query
Datomic is able to access datoms at memory speeds for queries whose supporting datoms are already in the cache. This latency is impossible to achieve with client/server databases. When not all supporting datoms are in cache, the wide branching factor of index trees ensures that at most 1-2 reads from storage are necessary to find the necessary segments.
Real-Time Query
The diagram below shows a cloud-based Datomic instance using DynamoDB for its storage layer. Index usage is visible in the Peer Library and Peer Server sections, where index segments are cached (the yellow "Cache") and merged with recent changes (the green "Live Index") to provide a real-time view to Query.

Partitions
Every Datomic entity is associated with a particular partition specified initially via tempid or the :db/force-partition directive. These partitions act as a coarse-grained grouping mechanism for entities, much as file cabinets act as a coarse-grained grouping mechanism for paper files.
Because the partition is encoded via high bits in the entity ID, entities in the same partition are sorted together in Datomic's two E-leading indexes, EAVT and AEVT. If the partitions align with usage patterns, this can improve performance. For example, consider a system with inventory, customers, and order partitions. A query for a particular item in inventory causes an "inventory" segment to be cached, and that segment contains a few thousand other inventory-related facts. If inventory queries tend to be followed by other inventory queries, this locality reduces the number of segments that a peer needs to cache. Conversely, if your application tends to access information about individual customers, it would be advantageous to put all of a particular customer's data in one partition and spread out your customers across thousands of implicit partitions.
Partitions also enable two techniques that are handy in larger systems: new entity scans and partition sharding.
New Entity Scans
Because Datomic stores information about time, it is easy to ask questions that apply only to recently created entities. For example, it is trivial in Datomic to run a batch job over everything that changed today, by grabbing the txRange of the log starting at midnight.
Such a scan does, however, have to consider all of today's datoms, filtering out any that are irrelevant to the task at hand.
It is possible to use partitions as a filtering mechanism when designing a system that needs to know about specific new entities (something that wants to respond to new events of a certain type, for example):
- Assign all the datoms for an event category to the same partition.
- Instead of using the log, use entidAt to fabricate an event id closest to the chosen start time t.
- Pass the fabricated entity id to seekDatoms to walk EAVT, walking entities ordered by time of creation and implicitly "filtered" by partition's impact on order.
Partition Sharding
Partition-based sharding is a technique for distributing entity-scoped read load to application servers. When dividing entities mechanically into N different groups at creation time, grouping together entities that are likely to be accessed together, it is possible to assign each group a different partition in Datomic. Then, at query time, direct entity-related queries to different application servers based on their partition. This causes the application servers to cache disjoint subsets of the total index, substantially increasing the fraction of the index that can fit into application server memory.
Partition-based sharding is an optimization only. Entities in any partition can still be reached by any peer.
Usage Notes
- Attributes that are going to be queried by value needs to be marked as :db/index true or :db/unique.
- Datomic's combination of indexes automatically supports queries associated with a number of different storage styles, including row-oriented, column-oriented, document-oriented, K/V, and graph.
- Datomic's EAVT and VAET indexes can automatically navigate entity relationships in both directions, so it is not necessary or recommended to create two attributes that model the same relationship but from different directions.
- Datomic programs do not need to do any API-level caching. Caching is generic, omnipresent, and requires little or no configuration.
- For small enough databases, the entire database is in peer caches, which makes data access faster than in client/server databases.
- The overhead of a peer cache miss is 1-2 segment fetches. From memcached, such fetches are on the order of 1 millisecond. Storages vary from 1 up to 10 or more milliseconds.
- The peer cache insulates Datomic from the performance of the underlying storage system. As a result, it is necessary to weigh storage performance somewhat less heavily than other systems.
- Background indexing needs to be fast enough to keep up with transaction load. To see more about capacity, check the Capacity documentation.