Transactions
All writes to Datomic databases are protected by ACID transactions. Transactions are submitted to the system's Transactor component, which processes them serially and reflects changes out to all connected peers. This document describes transactions in detail.
Topics covered in this page include:
- Transaction structure
- Transaction execution
- Identifying entities
- Building transactions
- Controlling partition assignment
- Built-in Transaction Functions
- Processing transactions
Transaction structure
Datomic represents transaction requests as data structures. This is a significant difference from SQL databases, where requests are submitted as strings. Using data instead of strings makes it easier to build requests programmatically.
A transaction request is a collection of list and/or map forms. Transaction requests represent unordered sets, but for convenience we write them as lists.
List forms
There are two kinds of list forms. A primitive list form requests the addition of an assertion (:db/add) or retraction (:db/retract) of a particular entity/attribute/value.
[:db/add entity-id attribute value] [:db/retract entity-id attribute value]
A list beginning with any element other than :db/add or :db/retract requests invocation of a transaction function.
[transaction-fn args*]
Map forms
The map form is a shorthand for a set of one or more assertion requests. The map may include a :db/id key identifying the entity that the map refers to. It may additionally include any number of attribute + value pairs.
{:db/id entity-id
attribute value
attribute value
... }
Datomic expands map forms into a set of :db/add forms. Each attribute/value pair becomes a :db/add. If you do not provide an entity-id, Datomic will generate a temporary entity-id.
[:db/add entity-id attribute value] [:db/add entity-id attribute value] ...
As a convenience for languages lacking a keyword type, attribute keys in a map form can be stringified keywords instead of keywords.
Transaction execution
Datomic expands list and map forms recursively until all that remains are a set of primitive assertion and retraction requests. Datomic then applies the transaction, producing a new immutable database value. Next, Datomic checks predicates and entity specs. Finally, Datomic logs the transaction and then broadcasts notifications to peers.
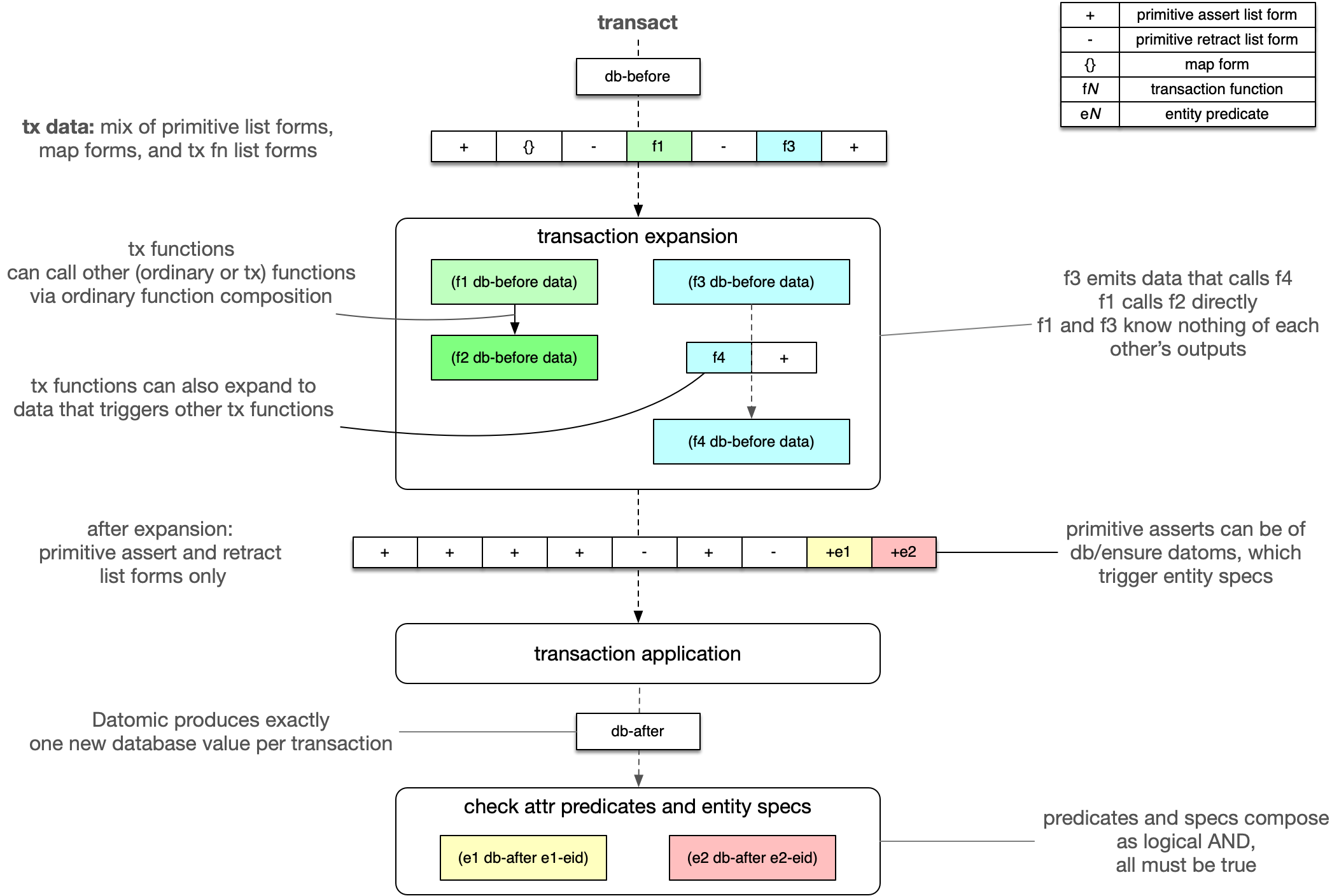
Each of these steps is described in more detail below.
Transaction Expansion
There are three different kinds of forms in a transaction request.
Assert and retract list forms are requests to add assertion and retraction datoms to the database. These are primitive and cannot be expanded further.
Map forms are a shorthand for assertion list forms, and are expanded mechanically.
Transaction functions are expanded by user code. When Datomic expands a transaction function, it looks up the function named by the first element of the list. It then calls the function, passing as arguments the database value as of the start of the transaction (db-before), followed by any arguments in the list. For example, the following transaction function
[:audit/authorize "stu@example.com"]
Triggers an invocation of a user-provided audit/authorize function
with the following arguments:
(authorize db-before "stu@example.com")
Successful transaction functions must return transaction request data, i.e. list and map forms. These can include more transaction functions, which are expanded recursively until all that remains are primitive assert and retract requests.
Transaction expansion resolves lookup-refs against db-before.
In addition to producing data, transaction functions can impose arbitrary functional constraints based on db-before and their inputs, aborting a transaction by calling cancel.
Transaction expansion is functional. Each individual transaction function should be a pure function:
(db-before, tx-request-data) -> tx-request-data
Then, the entire process of transaction expansion can be viewed as a function
(db-before, tx-request-data) -> primitive-tx-request-data
Transaction Application
Once a transaction request has been expanded into a set of primitive list forms, Datomic applies the transaction. From the list forms, Datomic will produce a set of datoms that conforms with the database schema if possible. Logical steps in this process include e.g.
- Assigning the next database t and tx
- Assigning entity ids for temporary ids, upserting for any unique attributes
- Creating datoms by adding Tx to the E/A/V/Op in assert and retract list forms
- Eliminating any redundant datoms
- Adding retraction datoms to preserve cardinality-one invariants
Datomic will abort the transaction if it violates any of Datomic's schema invariants, e.g. if there is a unique conflict or if the transaction attempts to assert multiple values for a cardinality-one attribute.
Successful transaction application will produce a new, immutable database value (db-after). Note that this value is not yet durable or visible outside this transaction.
Transaction application as a whole is also functional, and can be viewed as a function
(db-before, tx-request-data) -> db-after
Checking Predicates
If the transaction included any attributes with associated predicates, or asserted :db/ensure for any entity spec, Datomic will invoke these predicates and entity specs now. Entity specs are evaluated against the database value (db-after) resulting from the transaction.
Logging the transaction
After applying the transaction and checking any predicates or entity specs, Datomic commits the transaction, durably logging it to storage and awaiting acknowledgment before broadcasting notification to connected peers. The complete serialization of transactions provides strong ACID guarantees.
Identifying entities
There are three ways to specify an entity id:
- a temporary id for a new entity being added to the database
- an existing id for an entity that's already in the database
- an identifier for an entity that's already in the database
They are described in the sections below.
Temporary ids
When you are adding data to a new entity, you identify it using a temporary id. Temporary ids get resolved to actual entity ids when a transaction is processed.
Creating tempids
The simplest kind of temporary id is a string that follows these rules:
- a temporary id cannot begin with a colon (:) character
- the temporary id "datomic.tx" always identifies the current transaction
- other strings beginning with "datomic" are reserved for future use by Datomic
In the transaction data below, the temporary id "jdoe" is used to indicate that the two datoms are both about the same entity:
[[:db/add "jdoe" :person/first "Jan"] [:db/add "jdoe" :person/last "Doe"]]
Temporary id resolution
When a transaction containing temporary ids is processed, each unique temporary id is mapped to an actual entity id. If a given temporary id is used more than once in a given transaction, all instances are mapped to the same actual entity id.
In general, unique temporary ids are mapped to new entity ids. However, there is one exception. When you add a fact about a new entity with a temporary id, and one of the attributes you specify is defined as :db/unique :db.unique/identity, the system will map your temporary id to an existing entity if one exists with the same attribute and value (update) or will make a new entity if one does not exist (insert). All further adds in the transaction that apply to that same temporary id are applied to the "upserted" entity.
Existing entity ids
To add or retract data about existing entities in a transaction, you must provide a lookup ref, entity identifier, or entity id.
If the entity in question has a unique identifier, you can specify the entity id by using a lookup ref. Rather than querying the database, you can provide the unique attribute, value pair corresponding to the entity you want to assert or retract a fact for. Note that a lookup ref specified in a transaction will be resolved by the transactor.
[{:db/id [:customer/email "joe@example.com"]
:customer/status :active}]
;; or using an entity id directly (rare)
[{:db/id 17592186046416
:customer/status :active}]
Entity identifiers
The system defines a special attribute, :db/ident, that can be used to assign an keyword identifier to a given entity. If an entity has a :db/ident attribute, its value can be used in place of the entity's id.
This mechanism is what allows you to refer to attributes, partitions, types, etc., by specifying keywords.
You can also use :db/ident to define entities representing enumerated values that can then be referred to by name (as described in Schema).
In the example below, the entity is specified by the ident :person/name:
[:db/add :person/name :db/doc "A person's full name"]
Building transactions
This section explains how to build transactions to add and retract facts. Each example shows a single transaction, but you can combine adding and retracting in a single transaction if desired.
Adding data to a new entity
To add data to a new entity, build a transaction using :db/add implicitly with the map form (or explicitly with the list form), a temporary id, and the attributes and values being added.
This example builds a transaction that creates a new entity with two attributes, :person/name and :person/email.
[{:person/name "Bob"
:person/email "bob@example.com"}]
This code constructs the same transaction programmatically.
tx = Util.list(Util.map(":person/name", "Bob", ":person/email", "bob@example.com"));
Note that there is no requirement about which attributes are added to which entities, this is left entirely up to your application. This provides a great deal of flexibility as your system evolves.
Adding data to an existing entity
To add data to an existing entity, build a transaction using :db/add implicitly with the map form (or explicitly with the list form), an existing entity id or entity identifier, and the attributes and values being added.
This example uses a lookup ref for an existing entity in a new transaction to change the value of the entity's :person/name attribute to "Robert".
[{:db/id [:person/email "bob@example.com"]
:person/name "Robert"}]
If you want to transact data about a set of entities matching more complex criteria than a single lookup ref, you can find entities with an arbitrary query.
Adding entity references
Attributes of reference type allow entities to refer to other entities. When a transaction adds an attribute of reference type to an entity, it must specify an entity id as the attribute's value. The entity id specified for the value may be a temporary id (if the entity being referred to is being created by the same transaction) or a real entity id (if the entity being referred to already exists in the database).
This example shows the literal representation of a transaction that creates two new entities, people named "Bob" and "Alice". Each entity has a reference to the other, connected using temporary ids, "bobid" and "aliceid", respectively. All instances of a given temporary id within a transaction will resolve to a single entity id.
[{:db/id "bobid"
:person/name "Bob"
:person/spouse "aliceid"}
{:db/id "aliceid"
:person/name "Alice"
:person/spouse "bobid"}]
This example shows constructing the same transaction from code.
tx = Util.List( Util.map(":db/id", "bobid", ":person/name", "Bob", ":person/spouse", "aliceid"), Util.map(":db/id", "aliceid", ":person/name", "Alice", ":person/spouse", "bobid"));
Cardinality many transactions
You can transact multiple values for a :db.cardinality/many attribute at one time using a list. The following example transacts a person named "Bob" with multiple aliases:
[{:db/id #db/id[:db.part/user]
:person/name "Bob"
:person/email "bob@example.com"
:person/aliases ["Robert" "Bert" "Bobby" "Curly"]}]
Nested maps in transactions
Often, a group of related entities are created or modified in the same transaction. Nested maps allow you to specify these related entities together in a single map. If an entity map contains a nested map as a value for a reference attribute, Datomic will expand the nested map into its own entity. Nested map expansion is governed by two rules:
- If the nested map does not include a :db/id, Datomic will assign a :db/id automatically, using the same partition as the :db/id of the outer entity.
- Either the reference to the nested map must be a component attribute, or the nested map must include a unique attribute. This constraint prevents the accidental creation of easily-orphaned entities that have no identity or relation to other entities.
As an example, the following data uses nested maps to specify two line items belonging to an order:
[{:db/id order-id
:order/lineItems [{:lineItem/product chocolate
:lineItem/quantity 1}
{:lineItem/product whisky
:lineItem/quantity 2}]}]
Notice that
- The two line items do not need to specify a :db/id, and will automatically get ids in the same partition as the order-id entity.
- Since the line items do not have unique ids, you can infer that :order/lineItems must be a component attribute. (This is sensible given the domain. Line items have no independent existence outside orders.)
Nested maps are often much more convenient than their equivalent flat expansions. The data below shows the same information order and line items as three independent entity maps.
[{:db/id order-id
:order/lineItems [item-1-id, item-2-id]}
{:db/id item-1-id
:lineItem/product chocolate
:lineItem/quantity 1}
{:db/id item-2-id
:lineItem/product whisky
:lineItem/quantity 2}]
In addition to being more verbose, this form requires additional work to explicitly manage item-1-id and item-2-id and their connections to the containing order.
Retracting data
To retract data from an existing entity, build a transaction using :db/retract, an existing entity id or entity identifier, the attribute, and optionally value being retracted. If a value is not provided, all values for the provided entity and attribute will be retracted.
This example queries for an existing entity id and uses it in a new transaction to retract the value of the entity's :person/name attribute.
bob_id = Peer.query( "[:find ?e . :in $ ?email :where [?e :person/email ?email]]", conn.db(), "bob@example.com"); tx = Util.list(Util.list(":db/retract", bob_id, ":person/name", "Robert"));
The following example accomplishes the same thing with a lookup ref.
tx = Util.list(Util.list(":db/retract", Util.list(":person/email" "bob@example.com"), ":person/name", "Robert"));
And the following retracts all values of the entity's :person/name attribute.
tx = Util.list(Util.list(":db/retract", Util.list(":person/email" "bob@example.com"), ":person/name"));
Datomic keeps the values of data over time and allows you to query the value of the database as of a point in time. That means it's possible to recover data even after it has been retracted, simply by querying a database value from the past.
Controlling partition assignment
To control partition assignment for tempids, entity maps can include the :db/force-partition or :db/match-partition directives. These directives allow you to request partition assignment for any new entity id created by a transaction.
Because partition directives are separate maps, they encourage keeping partition policy separate from entity data, and make it easier to write supporting code that manage partitions across many transactions.
:db/force-partition
The value of :db/force-partition is a map from tempids to desired partitions. Named partitions are specified by a keyword, such as :orders below.
[{:db/id "order"
:order/lineItems ["item1", "item2"]
{:db/id "item1"
:lineItem/product chocolate
:lineItem/quantity 1}
{:db/id "item2"
:lineItem/product whisky
:lineItem/quantity 2}
{:db/force-partition {"order" :orders
"item1" :orders
"item2" :orders}}]
Implicit partitions are specified by entity id, found by calling db.part or implicit-part. The example below transacts "customer" and "order" into implicit partition 343:
[{:db/id "customer"
:customer/order "order"}
{:db/id "order"
:order/id "55555"}
{:db/force-partition {"customer" (d/implicit-part 343)
"order" (d/implicit-part 343)}}]
:db/match-partition
Sometimes it is more convenient to request a partition via an entity in the same partition, rather than the partition id. The value of :db/match-partition is a map from tempids to entities in desired partitions.
The following example transacts line items into the same partition (implicit part 500) as their containing order:
[{:db/id "order"
:order/lineItems ["item1", "item2"]}
{:db/id "item1"
:lineItem/product chocolate
:lineItem/quantity 1}
{:db/id "item2"
:lineItem/product whisky
:lineItem/quantity 2}
{:db/force-partition {"order" (d/implicit-part 500)}
:db/match-partition {"item1" "order"
"item2" "order"}}]
The Tempid Data Structure
As an alternative to string tempids, peers (but not clients) can choose to make a structural tempid.
You can make a temporary id by calling the datomic.Peer.tempid method. The first argument to Peer.tempid is the partition where the new entity will reside as an argument. Partitions can be referred to by name, or you can use an implicit partition.
You should use :db.part/user or an implicit partition for your application's entities. You can also create one or more named partitions of your own, as described in Schemas.
This code gets a new temporary id in the :db.part/user partition.
temp_id = Peer.tempid(":db.part/user");
Each call to tempid produces a unique temporary id.
There is an overloaded version of tempid that takes a negative number as a second argument. This version of tempid creates a temporary id based on the number you pass as input. If you invoke it multiple times with the same partition and negative number, each invocation will return the same temporary id. This can be useful when constructing transactions that add references between entities, as explained below.
In some cases, you may want to store the literal representation of a transaction in a file. The literal form can be read with datomic.Util.read and submitted as a transaction. This is a useful way to store a schema definition, for example.
You can insert temporary ids into the literal representation of a transaction using the following syntax:
#db/id[partition-name value*]
where partition-name is the name of a partition in the system and the value is an optional negative number.
When the literal representation of a transaction is parsed, this syntax is interpreted and a temporary id is generated.
Default Partition
String tempids create entities in the default-partition for the transactor process (unless the transaction contains a :db/force-partition or :db/match-partition directive controlling its partition assignment.) You can set the default partition by editing the transactor properties file:
default-partition=:my.namespace/my-partition
If no default partition is specified, the transactor will use the built-in :db.part/user partition.