
Analytics Support (Preview)
Concept
Datomic is a system of facts - values of attributes of entities. This is a rich model well suited for information programming, and Datomic's query language fits seamlessly into the information programming model of Clojure.
However, you may have other members of your team - data scientists, analysts, operations people et al who need to leverage the information stored in Datomic but are not versed in Clojure. Instead, they might have skills in Python, R, SQL, or high-level analytics tools like Metabase, Tableau, or Superset. The analytics support preview provides access to Datomic for these users, via those tools and more.
How It works
Analytics tools invariably expect data to be in rectangles. While there are many ways to present data as rectangles (CSV files etc), all analytics tools support data from relational, SQL sources.
The Datomic team developed a Datomic connector for the SQL query engine Presto SQL, and bundled the connector in a Presto server distribution. Presto in turn supplies a SQL command-line interface.
Check configuration for further information.
There is native Presto protocol support for Python, R, Metabase, Superset, Tableau, and more. Presto also supports JDBC for integration with Java-based analytics tooling. In short, if you are looking to connect an analytics tool to Datomic, you will look for the Presto connector, or use JDBC.
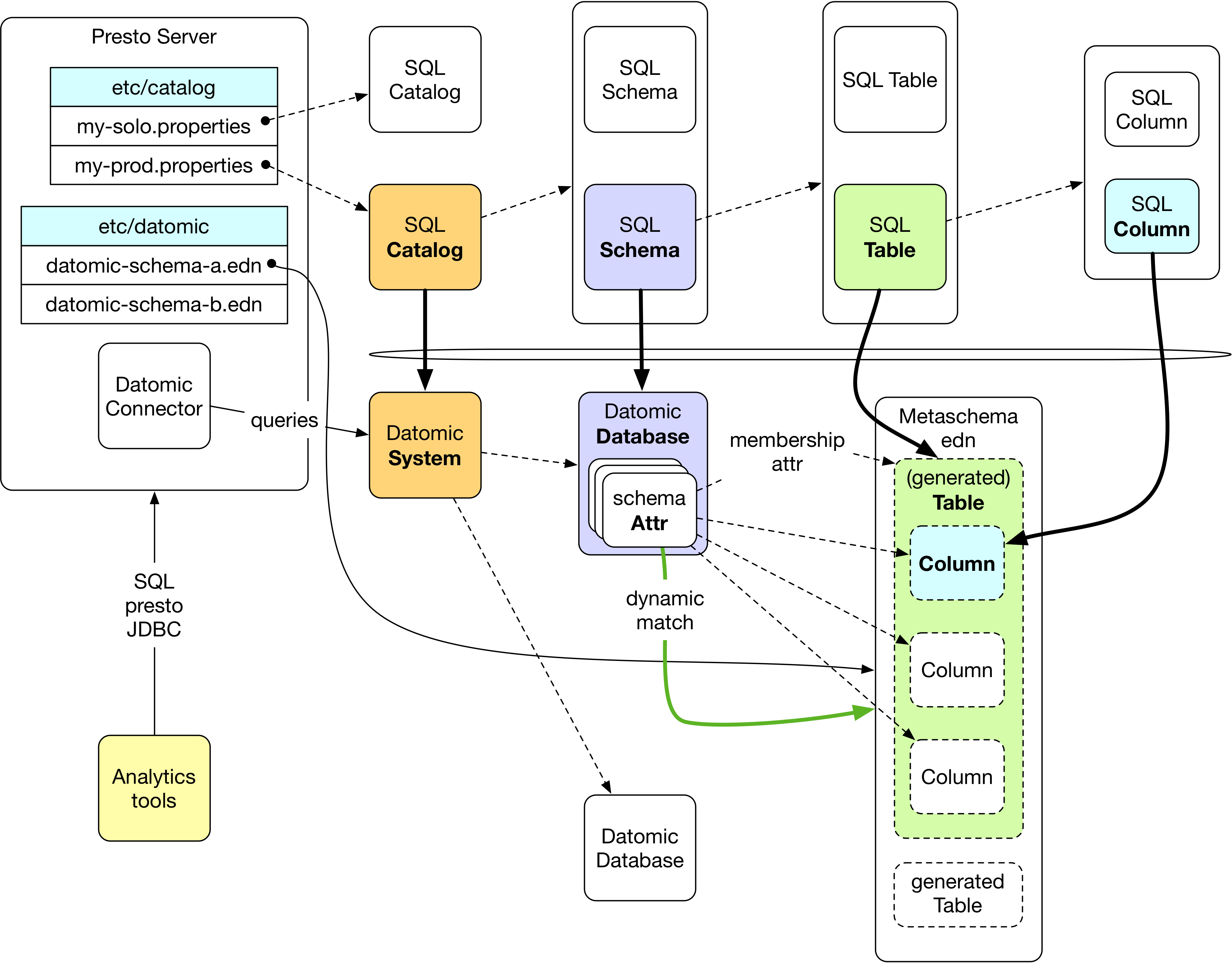
SQL Mapping
The SQL information model is one of the:
- Catalogs: data places and collections of schemas
- Schemas: collections of tables
- Tables: relations
and their columns.
You will create a catalog properties file (Java style) to dynamically expose each Datomic system as a SQL 'catalog', and its databases as SQL 'schemas'.
For each Datomic schema you use (perhaps shared across one or more databases) you will create a metaschema EDN file, giving the file a name ending in .edn, which determines which SQL tables are available and their columns.
Metaschemas
To generate dynamic SQL tables and columns from Datomic entities and attributes, it's necessary to determine:
- What are the tables?
- Which entities are in each table?
- Which attributes will provide its columns?
Metaschemas are EDN files ending with a .edn extension that, with minimal entries, answer these questions.
Membership Attributes
Membership attributes (attrs) determine both which tables are generated and which entities are in each table. For each membership attr at least one table is generated, as mentioned in the cardinality-many discussion below. If an entity has the membership attr, it is in the table, and if it does not have that attr it isn't in the table.
The top-level :tables entry of a Metaschema is simply a map with membership
attrs as keys, and options maps as values.
Namespace Conventions Determine (Default) Columns
The Metaschema is designed to be minimal - you can supply more directives in the options maps, but nothing else is required. The default generation leverages the Datomic convention of putting (most of) the attributes used for a 'kind' of entity in the same namespace.
For example, here's what you'll get if you choose :product/code as a membership attr with an empty options map:
- A table named with the namespace part of the membership attr - "product"
- A row in that table for every entity that has a value for :product/code, even if they don't have values for other attrs/columns
- A column in that table called "db__id", containing the entity id
- A column in that table for every cardinality-one attr in the namespace :product, named with the name part of the attr – E.g. :product/name becomes a column called "name" with a type of varchar
Note that nothing about this convention limits you - you can exclude some default columns, include attrs from other namespaces, control the generated table and column names, etc. Check the Metaschema reference for details.
An Additional Table Is Generated per Cardinality-Many Column
Since SQL columns are single-valued, cardinality-many (card-many) attrs need special handling. For each card-many column included either via the namespace defaults or explicitly, another table is generated containing all of the card-one columns of the base table plus a column for the card-many attr. Thus there will be repeating groups as there would be in a join.
For example, if there was a card-many attr called :product/tags, you would get:
- Another table called "product_x_tags"
- With the "db__id", "name" etc columns from above, which may repeat
- Plus a column called "tags"
Column Joins - More Denormalizing Power
While analytics tools work with SQL, many are happiest to be supplied with wide, denormalized data sets rather than constructing and manipulating SQL joins in the tool. Normally one would accomplish this by encapsulating the joins in SQL views. However such views would have to be duplicated in all DBs that share the same schema, and performing those joins in the presto engine is less efficient than doing so in Datomic. To facilitate the construction of these 'wide' views, the Metaschema system provides column joins.
The :joins map maps ref attrs to tables already defined by the Metaschema.
When that attr contributes to a table, the columns of the joined table are included as well.
For example, if there was a "country" table based on :country/code containing
columns "code" and "name" for :country/code and :country/name, and a ref attr
called :product/country, there would be an integer column in the "product" table called "country",
containing the id of a country. Adding an entry in the :joins map of {:product/country "country"}
would add "country__code" and "country__name" columns to the "product" table.
Check the Metaschema reference for more details.
One Metaschema per Datomic Schema
Quite often you might have multiple databases in a system that use the same schema. You need to create a Metaschema for each Datomic schema, not for each database.
The association of a Metaschema with a database is done dynamically - if a database has all of the membership attrs of a Metaschema, that Metaschema will be used to generate tables for that database.
It's All Virtual
It's important to note that the various wide and denormalized tables implied above are not pre-realized. They take no space. They are generated on the fly and only to the extent needed, i.e. you will only incur the cost to retrieve those columns you select. The card-many and column joins are more efficient than the equivalent SQL joins and views would be.
Preview Status
Analytics support is in preview. Note that:
- Details are subject to change
- Some performance optimizations are not included in the preview release
- The Datomic team is interested in your feedback