
Introduction
Datomic is a general purpose database system designed for data-of-record applications. A Datomic database is a set of immutable atomic facts called datoms. Datomic transactions add datoms, never updating or removing them, so you have a complete audit trail and the ability to query “as of” points in time. Datomic transactions are serialized in a total order, providing strong ACID guarantees.
Datomic has a powerful and flexible information model. Each Datomic database declares an attribute-level schema, and any entity can possess any attribute. You can query your data with datalog (a logic-based query language), and navigate arbitrary hierarchies with pull. Datomic’s indexes automatically support many access patterns common in SQL, column, K/V, hierarchical, and graph databases.
Datomic’s information model scales to a wide variety of different use cases:
- Datomic Local is an embedded, single-process database.
- Datomic Pro is a distributed database with arbitrary read scaling, pluggable storage, and the ability to run on-premises or in the cloud.
- Datomic Cloud is a distributed database that runs on AWS, with automation to manage clusters of Datomic processes serving web and AWS Lambda requests.
Datomic is developed and maintained by Nubank, where it is used in billions of user transactions every day. Datomic is used by hundreds of companies around the world in diverse domains including finance, healthcare, law, retail, and science. Datomic is written in Clojure and runs on the Java Virtual Machine (JVM). All editions of Datomic are free, with binaries licensed under the Apache 2.0 license.
About The Overview
This overview provides a concise description of Datomic, with links to the reference docs for comprehensive detail. After reading this overview, you will know whether and where Datomic might be useful to you, which edition of Datomic to choose, and how to get started learning Datomic.
The overview sections are:
- Information model: Datomic’s information model, and how that model maps to real-world use cases
- Architecture: the philosophy behind Datomic, Datomic’s key data structures, and the topologies of Datomic deployment
- Datomic editions: a comparison of Datomic Local, Datomic Pro, and Datomic Cloud
- Datomic APIs: a comparison of Datomic’s peer and client APIs
For many people, the most efficient way to begin learning Datomic is to read this overview in its entirety, following the links to the reference for more detail as needed. If you prefer a more hands-on introduction, start with the tutorial using the Datomic Pro peer library.
Information Model
A Datomic database is a single universal relation of facts called datoms. Datoms can be either assertions indicating that something is known to be true at a point in time or retractions indicating that something is no longer known to be true. Datoms are atomic and immutable. Datomic transactions atomically add a set of datoms to a database, they never update or remove anything. Each datom relates an entity id (E) to a value (V) via an attribute (A). Attributes have a schema; value type and cardinalities must be declared before an attribute is used. A value can be one of various built-in types, including entity ids. The E/A/V portion of a datom is similar to the triples of a traditional triple store. Each datom also includes the id of the transaction entity (Tx) that added it, and a boolean for whether the data is an assertion or retraction. Datoms sharing a common E can be projected into an entity, which is an associative (A->V) view of all assertions with a common entity id as of a given point in time. Datomic ensures that transactions are serialized in a total order, and this order can be accessed programmatically through the time t of each datom. Transactions are themselves entities, recording the wall clock time of the transaction along with any additional datoms you choose to add.
Benefits
The Datomic information model has the following benefits:
- Trivial read scaling: because databases are immutable, any number of processes can have copies of the data to serve read loads. Readers do not need to wait for or coordinate with any other process.
- The database within your application: application processes have their own copy of the query engine and database in local memory. This enables low-latency data access and supports access patterns that would be impractical with server roundtrips.
- Auditability: the total ordering of transactions and the fact that nothing is ever changed or removed means that you know and can demonstrate every step in the history of your data. The fact that transactions are themselves entities also offers an ideal place to store domain-specific provenance metadata.
- History: since every datom encodes its time "t", databases can be filtered to include only data as of any specific point in the past. Existing queries can be used against such “as-of” databases without modification.
- Powerful query: the universal relation of datoms is well suited for datalog+recursion, which has expressive power equivalent to the relational algebra behind SQL.
- Impedance-free data modeling: if you think of your domain entities as associative collections of facts, then your logical model translates directly to Datomic’s information model. This stands in contrast to solutions like the join tables required in SQL.
- Flexibility: any entity can possess any attribute, which is a great fit for real-world data where exceptions are the rule. Unlike traditional databases, there is no need for NULL - datoms either exist or they don’t.
- Efficiency across multiple read access patterns: Datomic data is indexed in many ways, including:
- By entity for “row” access (EAVT)
- By attribute and value for key/value lookup (AVET)
- By attribute for “column” access (AEVT)
- By (entity id) value for hierarchical or graph navigation (VAET)
Tradeoffs
There’s no such thing as a free lunch. Datomic’s information model has the following tradeoffs:
- No per-db write scaling: since transactions are totally serialized, only one transaction can occur at a time in a given database.
- Data constraint: not suitable for high churn, non transactional data like observability telemetry or logs.
- No structural “types”: Datomic’s universal schema means that all entities have the same universal type. While this is very flexible, it provides no declarative mechanism (e.g. tables) for structural requirements such as “a person must have a name”. Where needed, such structural requirements are enforced by transaction-time specifications.
In addition to these inherent tradeoffs, Datomic's current implementations do not have value types suitable for storing large documents, images, audio, or video. It is common practice in Datomic to store such data in a key/value store such as S3 and then store pointers to that data in Datomic. Datomic’s combination of benefits and tradeoffs makes it well suited for data of record in various domains including finance, law, the sciences, manufacturing, retail, wholesale, healthcare, and supply chain logistics. It is also well-suited for configuration data and local application state.
Architecture
This section covers Datomic’s architecture from three perspectives: its inspirations from Clojure, the data structures that give Datomic leverage over data, and the topology of Datomic deployments.
Inspired by Clojure
Datomic is designed and implemented by the creators and maintainers of the Clojure programming language, and the two share design sensibilities. Having familiarity with Clojure is a great help in understanding the Datomic architecture, in particular:
- Datomic, like Clojure, encourages functional programming with dynamic typing as a way to create robust and flexible systems.
- A Datomic database value is a persistent data structure, similar to Clojure’s collections.
- A Datomic transaction is a functional, atomic update to a database value, similar to using swap! on a Clojure atom.
- Datomic entities are open, similar to Clojure maps, instead of being based on a fixed set of slots as is typical in object-oriented programming and SQL tables. Please refer to the “just use maps” section (3.4.2) in the history of Clojure paper for further details.
- The Datomic team shares the Clojure team’s commitment to stability. As Datomic evolves, we seek growth instead of breaking change and semantic versioning, as described in Rich Hickey’s Spec-ulation talk (transcript). You should be able to use Datomic in your programs for decades with minimal to no modification.
Data Structures
Datomic has two key durable data structures: indexes and the log.
Indexes
A Datomic database is logically a set of datoms. To make this structure practical for use, Datomic provides leverage via indexes and query capabilities that use those indexes.
Datomic maintains four different indexes designed to support different access patterns. Each index is implemented as an immutable, persistent tree with a wide branch factor (typically thousands of items). In storage, each node of an index tree is a separate segment, similar to pages in a traditional relational database management system (RDBMS).
| Index | Sort order | Contains |
|---|---|---|
| EAVT | entity / attribute / value / tx | all datoms |
| AEVT | attribute / entity / value / tx | all datoms |
| AVET | attribute / value / entity / tx | Pro: :db/unique or :db/index attributes Cloud/Local: all datoms |
| VAET | value / attribute / entity / tx | :db.type/ref attributes |
Datomic’s query and pull APIs use appropriate indexes transparently. The segments of an index are immutable and can be cached anywhere, for example: inside an application’s process-local object cache, in a memory-backed cache like memcached, or an SSD backed cache such as Valcache. When a query requires a segment, it first checks the object cache. On a miss, it then populates the object cache from cache/storage. This has the following implications:
- Databases can exceed the size of application memory, with most of the database available through tiers of least-recently-used (LRU) caches.
- Application processes can access a portion of the database at memory speed without requiring client/server interaction. If an application process has sufficient memory for its typical working set, then its query performance will be comparable to that of an in-memory database.
- Each distinct process has its own object cache, which automatically caches the working set for that process without requiring user configuration. Consequently, a single system can efficiently serve very different load patterns by simply directing the requests for each load pattern to a different set of instances.
Datomic uses an efficient algorithm to construct indexes, achieving time complexity that is sublinear in the overall size of the database. In addition, all Datomic processes cache the most recent transactions in memory, so that indexes need not be rebuilt continually and can be rebuilt occasionally in the background.
Log
Datomic’s transaction log is an index sorted by time t. Each time t represents a single transaction. There is no ordering within a transaction, which is a set of datoms. Different Datomic editions employ different data structures for the log, all of which are indelible, chronological, transactional, and tangible:
- Indelible: The log accumulates new information and never removes existing information. Where update-in-place databases would delete, Datomic instead adds a new retraction.
- Chronological: The log contains the complete history of the database, in chronological order.
- Transactional: Datomic writes are always ACID transactions, serialized in a total order.
- Tangible: The log in Datomic is not just an implementation detail; it is an integral part of Datomic's information model. You can query the log using the log API.
Topology
Datomic decomposes the capabilities of a traditional RDBMS into distinct services: transactions, query, catalog operations, indexing, caching, and storage. Different editions of Datomic deploy these services in different topologies to meet different requirements for cost, latency, and availability
All but the smallest Datomic deployments simplify the database into multiple highly-available service layers as follows:
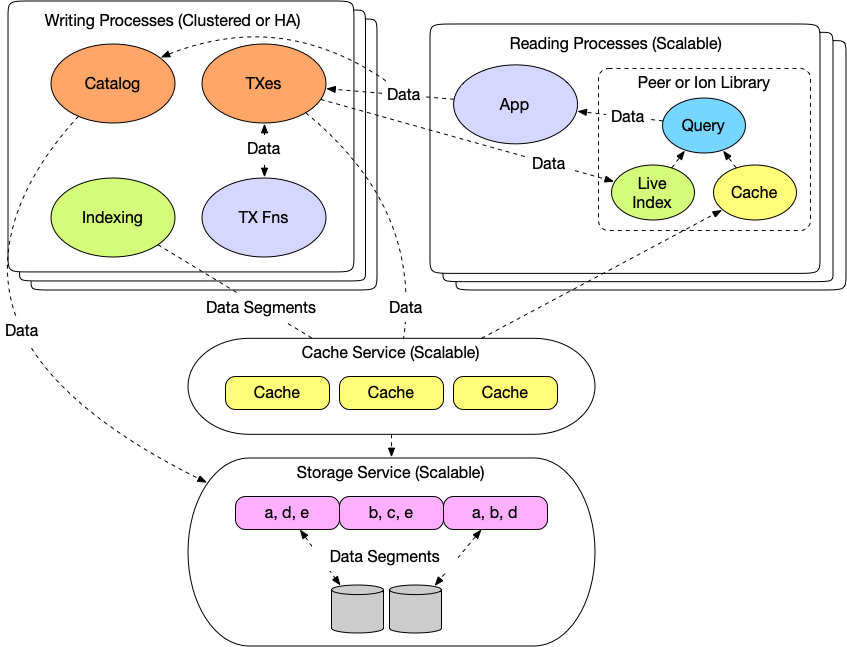
This topology supports the following objectives:
- The database lives inside your application, instead of in a separate process. Your application processes include the Datomic query engine as a library, and can be scaled to an arbitrary number of reading processes for both availability and throughput.
- Datomic is highly available for writes, with writing processes deployed either as an active/standby pair or in a cluster. User-defined transaction functions can perform arbitrary validations and transformations inside a transaction.
- Storage is a service separate from the rest of the database, and you can choose from different storage services based on your requirements for cost, latency, throughput, and availability.
- Multi-level caching is completely transparent to application code. Because data is immutable, caches require no coordination and are always valid.
- The pervasive use of immutable data in the API and in interprocess communication facilitates metaprogramming at every level.
- The live (recent) index in every application process eliminates the need to rebuild the indexes on every transaction.
Current Datomic editions combine transactions, catalog operations, and indexing in the same processes. This is not fundamental to Datomic’s design, and could be further simplified in the future.
Datomic Editions
Datomic is available in three editions: Local, Pro, and Cloud. The table below explores the differences in detail, but the choice is usually fairly straightforward:
- Datomic Local is an embedded database for use in a single process. It uses the local file system for storage, and is suitable for single-process applications that do not need high availability or scale.
- Datomic Pro is a distributed database supporting pluggable storage and scalable reads. When using Datomic Pro, you are responsible for provisioning storage and caches, as well as for managing the transactor processes for writes and application peer processes for reads. Datomic Pro offers the flexibility to run anywhere, making it the most versatile option.
- Datomic Cloud is a distributed database that runs exclusively on AWS. Datomic Cloud automates deployment for Datomic processes, application processes, SSD-backed caches, Auto Scaling groups, Application Load Balancers, and web and AWS Lambda application entry points. Datomic Cloud is the best fit for users who are committed to AWS and are willing to give up operational flexibility in return for abstracting away some of the complexity of running on AWS.
| Local | Pro | Cloud | |
|---|---|---|---|
| Deploy | Anywhere | Anywhere | AWS only |
| Supported APIs | Client | Client and Peer | Client |
| Storage | Local disk | Pluggable: DynamoDB, SQL, Cassandra, etc. | DynamoDB |
| Storage durability | Only as good as local disks | Excellent | Excellent |
| Storage availability | Poor, single machine | Excellent if replicated | Excellent, always replicated |
| Writes (transactions) | Embedded library | Single transactor process | Per-db primary cluster node |
| Write availability | Low, embedded library | Failover to standby transactor | Reroute to another cluster node |
| Indexing | No | On transactor process | On secondary cluster node |
| Reads in your application | Client library | Peer library | Client library + ions |
| Server capability | No | Peer-server | Cluster |
| Read availability | Low, embedded library | High with multiple peers | High with query groups |
| Scaling reads | No | Run multiple instances of your app or multiple instances of peer-server | Query group |
| Monitoring | No | Pluggable entry point Built-in CloudWatch integration |
CloudWatch |
| Caching tiers | No | BYO Memcache and/or Valcache | Integrated Valcache |
| Write deployment | Embedded library | You manage the transactor processes | CloudFormation template |
| Read deployment | Embedded library | You manage the peer processes | CloudFormation template |
| Routing application traffic | Up to you | Up to you | AWS ALB, API Gateway, Route53 |
| Access control | Up to you | Up to you | AWS IAM |
| Application deployment | Up to you | Up to you | Ions |
| Application entry points | Up to you | Up to you | Web and AWS lambda |
| Control over deployment | Very high | Very high | Limited configuration through CloudFormation template |
Datomic APIs
Datomic has two programmatic APIs, the client API and the peer API. Both APIs deliver access to the entire information model and architecture of Datomic discussed above. They differ in presumptions about data locality, communication mode, availability in Datomic editions, and access to some features specific to Datomic Pro.
- The client API makes no presumptions about the location of the query engine, which might be in the same process or might be across a client/server connection. The client API supports both synchronous and asynchronous communication modes. The client API is available in all Datomic editions, which makes it the best choice for library code that needs the greatest reach. The client API is the only choice for Datomic Cloud and Datomic Local.
- The peer API is the original Datomic API. The peer API has a superset of the features of the client API - because the peer API presumes that the database is always in your application process, it includes extra features that leverage this locality such as lazy entities. The peer API supports only synchronous communication and is available only in Datomic Pro. The peer API provides access to Datomic Pro-specific capabilities such as user control of partitions. The peer API is the best choice for applications that run and plan to always run on Datomic Pro, and who want the most powerful API available for that platform.
The table below explores the API differences in more detail:
| Peer | Client | |
|---|---|---|
| Key differences | ||
| Process local | Datomic Pro only | Datomic Cloud (via ions), Datomic Local |
| Remote client/server | No | Datomic Cloud |
| API style | Synchronous only | Sync or async |
| Common core operations | ||
| Catalog operations | Yes | Yes |
| Transactions | Yes | Yes |
| Query and pull | Yes | Yes |
| Index access | EAVT, AEVT, AVET, VAET | EAVT, AEVT, AVET, VAET |
| Time filters | As-of, since, history | As-of, since, history |
| Operations where peer API has extended capability | ||
| Transaction ordering | In order submitted from a peer | In order acknowledged (might vary from the submission order if client reaches different server) |
| Lazy entities | Yes | No |
| Partition control | Implicit partitions and explicit partitions | Implicit partitions |
| Predicate filters | Yes | No |
Get Started
Great! Now you have read the overview! What next? We recommend that you continue to Pro setup, and learn how to access Datomic by installing the peer API, and then completing the peer tutorial.