Growing Your System
This page covers topics that will help you improve the operation of Datomic as your system grows:
- Instance sizes
- Primary compute group
- Adding and scaling a query group
- Task-specific query groups
- Valcache for large datasets
- Scaling storage
- Understanding your AWS bill
- Reducing AWS costs
- Development workflow
Instance Sizes
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing-related costs, and the user only pays for the hardware that you use to run the system.
You can change your Datomic Cloud instance size at any time by updating the CloudFormation template. As the table below shows, moving up the t3 instance size chart provides more memory and more CPUs.
- Additional memory can improve the performance of queries and transactions
- Increasing the number of CPUs allows Datomic to serve more requests simultaneously, and can also improve the performance of individual queries and transactions
If you need maximum performance, consider i3 instances. They provide valcache, are not subject to unlimited mode usage charges, and require that you raise your AWS account limit.
| dev-local* | t3.small | t3.medium | t3.large | t3.xlarge | t3.2xlarge | i3.large | i3.xlarge | |
|---|---|---|---|---|---|---|---|---|
| (v)CPUs | any | 2 | 2 | 2 | 4 | 8 | 2 | 4 |
| GB RAM | any | 2 | 4 | 8 | 16 | 32 | 8 | 16 |
| default metrics | N/A | None | Basic | Detailed | Detailed | Detailed | 475 | 950 |
| 1 instance on-demand | $0 | $34 | $74 | $127 | $216 | $395 | $216 | $395 |
| 2 instances on-demand | n/a | $49 | $118 | $216 | $396 | $754 | $396 | $754 |
| 1 instance reserved | n/a | $28 | $62 | $104 | $172 | $306 | $172 | $306 |
| 2 instances reserved | n/a | $37 | $96 | $172 | $307 | $576 | $307 | $576 |
To develop and test your Datomic applications at no cost, use dev-local. For complete details on the monthly base price, check understanding your AWS bill.
Instance Defaults
The CloudFormation template provides settings for AutoScaling and Metrics level which are based on instance size:
| t3.small | t3.medium | t3.large | t3.xlarge | t3.2xlarge | i3.large | i3.xlarge | |
|---|---|---|---|---|---|---|---|
| Metrics | None | Basic | Detailed | Detailed | Detailed | Detailed | Detailed |
| AutoScaling desired | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
| AutoScaling minimum | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
| AutoScaling maximum | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| AutoScaling during update | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
Primary Compute Group
The primary compute group of a system performs all transactions, while queries can be performed by any compute group (primary or query). The primary compute group should not autoscale: it should run a fixed number of instances based on your transaction load and database count.
For a system with a single primary database or with a low total write volume, you should fix the size of the primary compute group at two instances. When you need to scale queries beyond what these two instances can support, add a query group.
If your system serves a high write volume across more than one database, you may want to run more than two instances in your primary compute group. Contact Datomic support if necessary.
Adding and Scaling a Query Group
When you first launch a Datomic system it has only a single compute group, the primary compute group described above. When you are ready to support higher query volume, you can add a query group. To add your first query group:
- Create a new query group with the same application name used by the original system
- Direct production traffic to this query group instead of the primary compute group
Datomic will automatically coordinate between query groups and the primary group, using the primary group for transactions and indexing.
Query Group Instance Size
Query group instances should typically be at least as large as the instances in the primary compute group. There are two reasons for this:
- Most systems spend more resources reading than writing.
- Query group instances "follow" the recent transactions in the primary compute group, which consumes both CPU and memory. If the query group instances are underpowered compared to the primary compute group, this following may consume so many resources that performance suffers.
Query Group Instance Count
You can set the minimum and maximum number of instances that will run in the group via the Cloudformation template. There are two reasons to increase the number of instances in a query group:
- Any number of instances greater than one will automatically enable high availability (HA).
- Each instance will increase the total amount of CPUs and memory available for Datomic queries. This will enable your system to serve a higher volume of queries.
Autoscaling Triggers
You can configure autoscaling triggers for a query group. These triggers should be based on a metric that measures when work is (or is close to) backing up. For example:
- If your system serves remote Datomic clients, then you can
scale on
HttpEndpointThrottled, which counts the number of client requests that were throttled because the system is busy. - If your system serves web requests, then you can scale on
HttpDirectThrottled, which counts the number of web requests that were throttled, or based on a domain-specific metric that you create.
Task-Specific Query Groups
If the usage of your system is homogeneous, one query group is all you ever need. You can simply expand that single query group to match the increasing query load. But in many cases, a growing system has more than one audience – in those cases, you can create additional query groups for different use cases. Simply start an additional query group for each distinct use case, and direct traffic for that use case to the query group's unique endpoints.
Tasks-specific query groups provide:
- The ability to scale resources independently for a task, without competing with other tasks
- The ability to turn off resources when not in use, for e.g. intermittent or one-off tasks
- Automatic, tuned-to-the-task caching without the need for configuring storage
A typical example of a multi-query group system is the following:
- An "app" query group that supports a production web application
- An "analytics" query group for live analytics, so that expensive analytics operations do not compete with the web application for resources
- A "support" query group for the operations team to query the system, without interfering with other users
Note that each query group can have its own instance size and group size, tuned to its availability, latency, and scalability requirements.
Valcache for Large Databases
Datomic Cloud automatically manages a multilayer cache that improves the performance of queries and transactions. If your system makes intensive use of a large database, you can further improve performance by enabling Valcache, an optional additional cache tier backed by SSDs on the primary compute group.
Datomic enables Valcache automatically when you choose an instance type in the i3 family. Before switching to i3, increase your AWS i3 instance limit.
Verify Your i3 Instance Limit
The default AWS limits on i3 instances will prevent Datomic Cloud from starting. Before you switch to an i3 instance type, check and update your i3 instance limit:
- Click on Limits in the EC2 dashboard menu
- Scroll down to find the
Running On-Demand All...which includesiinstances in the instance list - Open the Limits Calculator
- Add a number of i3 large instance types that is 2+ and corresponds to how high you plan to scale your system
- Ensure that your
Current limitis greater than thevCPUs needed. Ignore the "New limit" value, as this assumes that you are currently at your vCPU limit- If your
Current limitexceeds the number ofvCPUs neededthen click theRequest on-demand limit increaselink under "Options" - Request the number of vCPUs that match your planned system needs
- If your
Once complete, submit the form and you will receive confirmation from AWS once your instance limit has been raised
Scaling Storage
Datomic indexes are redundantly stored in S3 and EFS. These high-reliability, high-availability storages are automatically scaled by AWS, with no user configuration required.
Database logs are stored in a DynamoDB table named "[system]". This table is configured with provisioned throughput and a broad range of autoscaling for both read and write. For most systems, these settings are a good sweet spot: when the system is under low transaction load, autoscaling will turn throughput down, saving money. When the load increases, autoscaling will increase throughput to match.
That said, there are two situations where you may want to increase DynamodDB provisioning for the "[system]" table:
- If you have a very bursty transaction load, and your system is intolerant of increased latency before autoscaling kicks in, you can increase the DynamoDB write minimum
- If your system has a very high write volume, and you are seeing regular DynamoDB throttling of writes, you can increase the DynamoDB write maximum
The Datomic catalog is stored in a DynamoDB table named "[system]-catalog", configured with modest provisioned throughput. Catalog operations are very low volume, you should never need to adjust this table.
Understanding Your AWS Bill
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing-related costs, and the user only pays for the hardware that you use to run the system.
The total cost of running a Datomic system is the sum of the base price and the usage price.
- The base price is the total monthly price of services that are billed per unit time, usually per hour (e.g. EC2 instances) or per month (e.g. KMS keys). A running Datomic system has a well-known base price based on its configuration, regardless of how the system used.
- The usage price is the monthly total prices of services that are billed by some measure of utilization, e.g. data stored, data transferred, or autoscaled DDB provisioning.
All prices below are for us-east-1, and were most recently updated on May 17, 2021.
Base Price
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing-related costs, and the user only pays for the hardware that you use to run the system.
The base price for a Datomic system combines all the hourly and monthly components of Datomic into a single monthly price. These components are enumerated below:
Hourly Prices
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing related costs, and the user only pays for the hardware that you use to run the system.
Each compute group will have a single ALB, with an hourly price of $0.0225, plus an instance hourly price based on the numbers and types of instances you choose:
| Instance type | On-Demand | Reserved |
|---|---|---|
| t3.small | $0.0208 | $0.0130 |
| t3.medium | $0.0624 | $0.0429 |
| t3.large | $0.1248 | $0.0938 |
| t3.xlarge | $0.2496 | $0.1875 |
| t3.2xlarge | $0.4980 | $0.3746 |
| i3.large | $0.2340 | $0.1850 |
| i3.xlarge | $0.4680 | $0.3700 |
Monthly Prices
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing-related costs, and the user only pays for the hardware that you use to run the system.
| Resource | Monthly price |
|---|---|
| KMS key | $1.99 |
| Route53 | $0.50 |
| basic metrics | ~$7.00 |
| detailed metrics | ~$15.00 |
| metrics dashboard | $3.00 |
Basic metrics include all the metrics normally used by operators. Detailed metrics include the basic metrics, plus a number of additional metrics that are useful for Datomic support. The metrics dashboard is enabled whenever you select at least basic metrics. The metrics prices are approximate because AWS charges only for metrics recorded, and systems do not necessarily report every possible metric.
The instance sizes table calculates a base price from the information above using the following assumptions:
- A Datomic system with a single compute group
- Default metrics level
- No unlimited mode costs (see the next section)
Your AWS bill will show line items for each AWS service separately.
Usage Price
This section only applies to Datomic 990-9202 and lower. Newer versions of Datomic Cloud are free of licensing-related costs, and the user only pays for the hardware that you use to run the system.
Datomic uses several AWS services that have a pricing model based on use:
- Indexes are stored in S3 and EFS
- The log is stored in DynamoDB
- Internet access is via API Gateway
- t3 family unlimited mode
While the usage price is specific to your specific usage pattern, there are a few very useful rules of thumb:
- All of the usage-base services used by Datomic participate in the AWS "always free" tier. A system at low utilization (e.g. a system used to interactively develop a prototype) will typically fit entirely in the free tier and have a usage cost of $0.
- The base price will typically be higher than the usage price, until you have a lot of data or high request volume.
- Datomic's t3 instances are configured to run in unlimited mode. If an instance is under continuous high CPU load, there is an additional $0.05 per-instance-hour CPU credit charge. Check the AWS unlimited mode documentation for additional details. If your system incurs these CPU credit charges, you should consider switching to the i3 instance family.
Reducing AWS Costs
There are a number of things you can do to reduce the AWS costs for Datomic Cloud:
- Develop and test your code with dev-local, which has no cost
- Choose the smallest EC2 instance size that can handle your performance requirements
- If you intend to run a compute group for a long period of time, purchase AWS Reserved Instances
- If you have a compute group that is used intermittently, turn off the compute instances when they are not in use
Development Workflow
If you plan to support multiple environments with Datomic systems, keep the following points in mind:
- The Datomic system is the unit of AWS IAM access control. If different environments need to have different AWS controls, put them in separate Datomic systems.
- Within a Datomic system, the compute group is the unit of ion deployment. So a single system can host many applications simultaneously. These applications could serve entirely separate purposes, or they could be various revisions of the same functionality.
- Transaction functions execute only in the primary compute group. Deploy them there, not to a query group.
- The CodeDeploy application name is the unit of ion push. If you give different Datomic systems the same application name, they will all be able to deploy from the same push. This is probably what you want if you e.g. test an application in one system and release it in another.
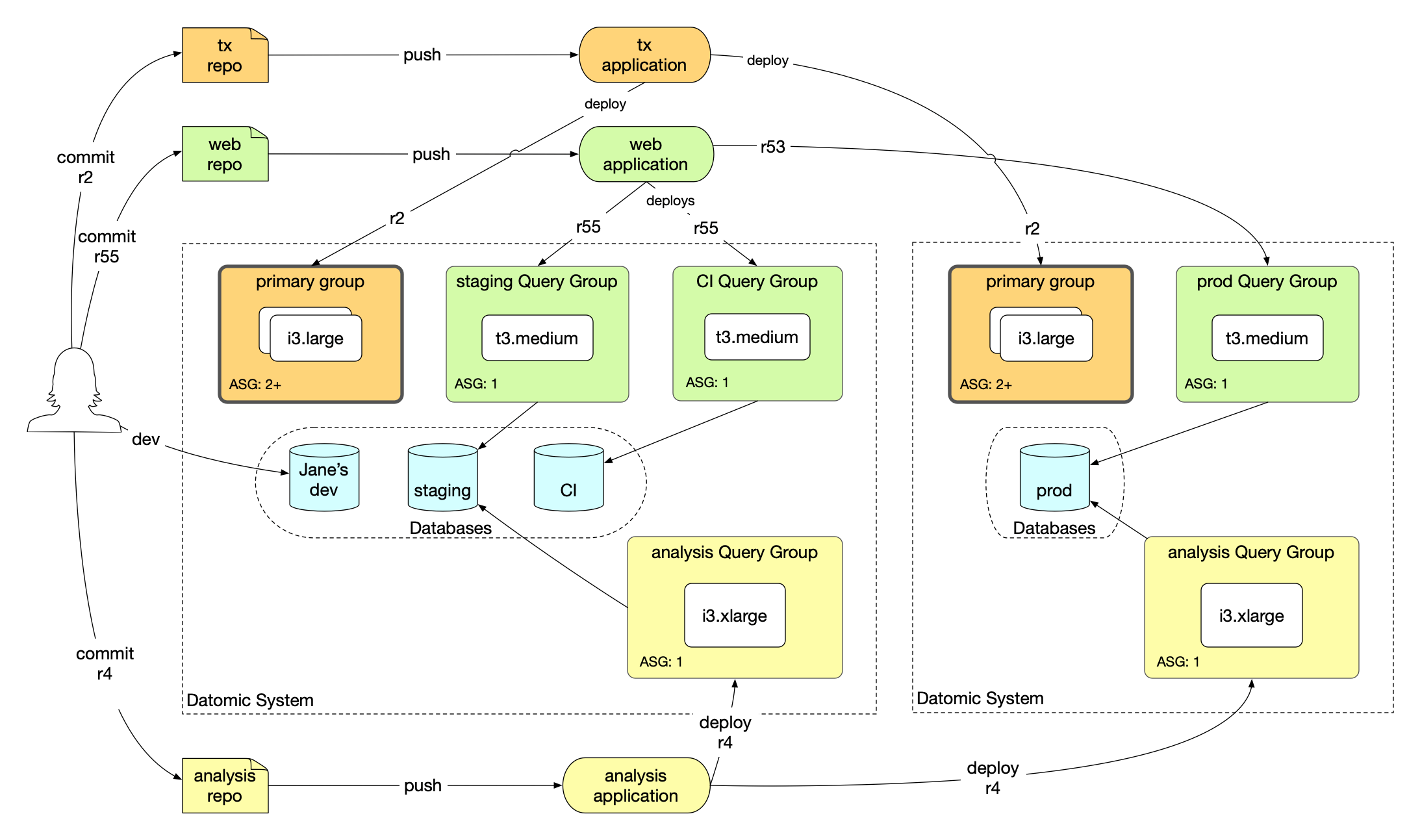
The picture below shows an example deployment designed to meet the following dev workflow objectives:
- Keep production code and data separate from all development work
- Support two different user bases that have different performance requirements: web app and analytics
- Demo and test code before deploying to production
- Allow developers to access test data from their laptops