
Datomic Cloud Architecture
Datomic's data model – based on immutable facts stored over time – enables a physical design that is fundamentally different from traditional RDBMSs. Instead of processing all requests in a single server component, Datomic distributes ACID transactions, query, datalog and pull, indexing, caching, and SQL analytics support to provide high availability, horizontal scaling, and elasticity. Datomic also allows for dynamic assignment of compute resources to tasks without any kind of pre-assignment or sharding.
Datomic is designed from the ground up to run on AWS. Datomic automates AWS resources, deployment and security so that you can focus on your application.
The Day of Datomic videos discuss Datomic architecture in detail.
System
A complete Datomic installation is called a system. A system consists of storage resources plus one or more compute groups:
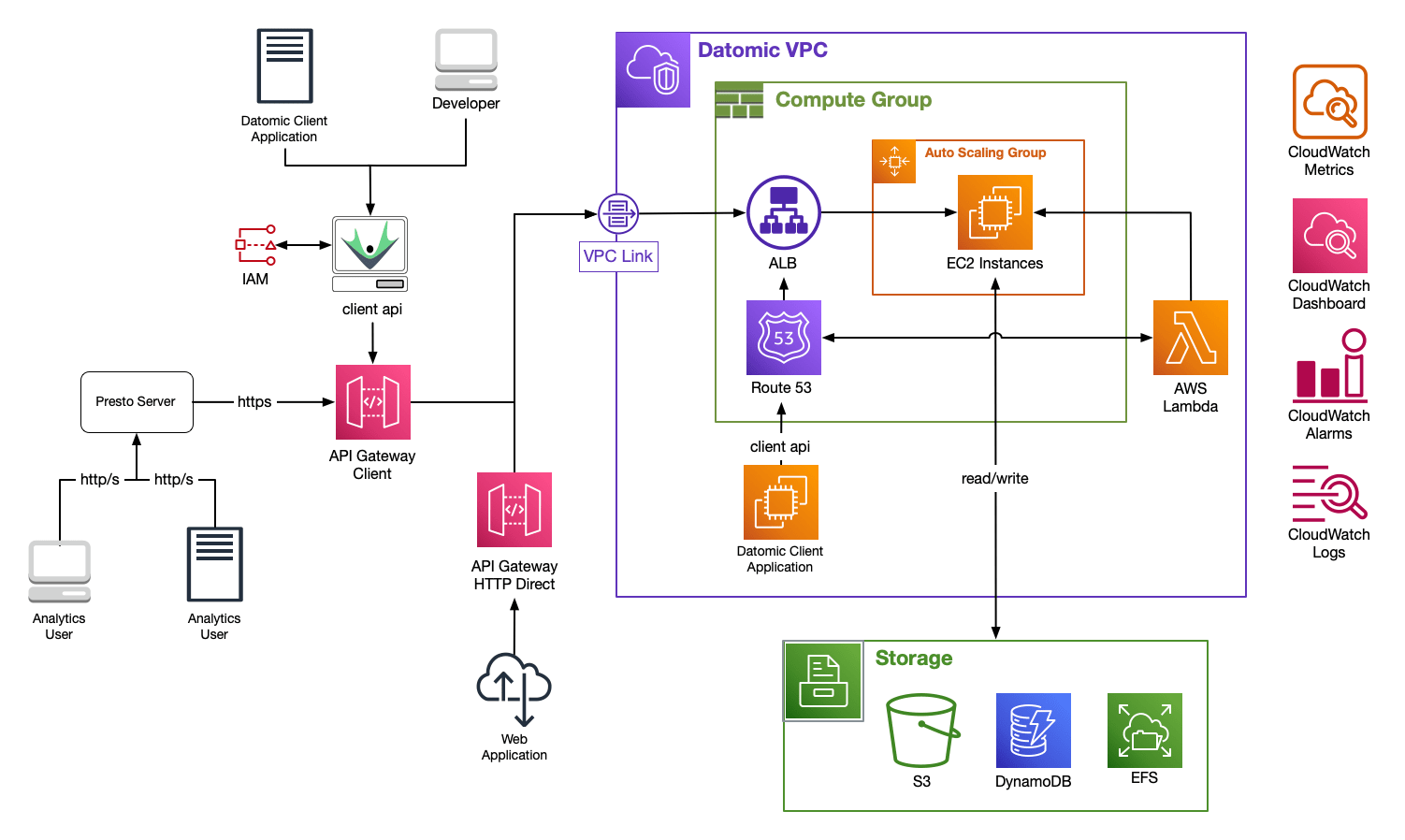
Storage Resources
The durable elements managed by Datomic are called Storage Resources, including:
- The DynamoDB Transaction Log
- S3 storage of Indexes
- An EFS cache layer
- Operational logs
- A VPC and subnets in which computational resources will run
These resources are retained even when no computational resources are active, so you can shut down all the active elements of Datomic while maintaining your data.
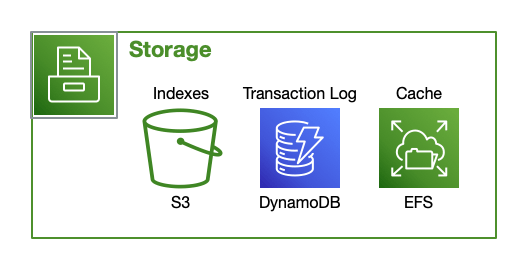
How Datomic Uses Storage
Datomic leverages the attributes of multiple AWS storage options to satisfy its semantic and performance characteristics. As indicated in the tables below, different AWS storage services provide different latencies, costs, and semantic behaviors.
Datomic utilizes a stratified approach to provide high performance, low cost, and strong reliability guarantees. Specifically:
Stratified Durability
| Purpose | Technology |
|---|---|
| ACID | DynamoDB |
| Storage of Record | S3 |
| Cache | Memory > SSD > EFS |
| Reliability | S3 + DDB + EFS |
| Technology | Properties |
|---|---|
| DynamoDB | Low-latency CAS |
| S3 | Low-cost, high reliability |
| EFS | Durable cache survives restarts |
| Memory & SSD | Speed |
This multi-layered persistence architecture ensures high reliability, as data missing from any given layer can be recovered from deeper within the stack – as well as excellent cache locality and latency via the multi-level distributed cache.
Indexes
Databases provide not just storage, but leverage over data. This leverage comes from two sources: useful indexes into data, and powerful query languages that use those indexes.
In Datomic Cloud, every datom is automatically indexed in four different sort orders, to automatically support multiple styles of data access: row-oriented, column-oriented, document-oriented, key/value, and graph. This makes it possible for the same database to serve a variety of usage patterns without the need for per-use custom configuration or data transformation.
Datomic's datalog query automatically uses the appropriate indexes. Datomic indexes are transparent to application code and configuration.
Log
The Datomic Cloud log is indelible, chronological, transactional, and accessible.
- Indelible: the log accumulates new information and never removes information. Where update-in-place databases would delete, Datomic instead adds a new retraction.
- Chronological: the log contains the entire history of the database, in time order.
- Transactional: Datomic writes are always ACID transactions, recorded with compare-and-swap operations against DynamoDB.
- Tangible: rather than being an implementation detail, the log is part of Datomic's information model. You can query the log directly with the log API.
Large Data Sets
Datomic is designed for use with data sets much larger than can fit in memory, while providing in-memory performance for query to the extent that memory is available. To support large data sets, Datomic:
- Stores indexes as shallow trees of segments, where each segment typically contains thousands of datoms.
- Merges index trees with an in-memory representation of recent change so that all processes see up-to-date and consistent indexes.
- Creates new index trees only occasionally, via background indexing jobs.
- Uses an adaptive indexing algorithm that has a sub-linear relationship with total database size.
- Transparently manages a multi-layer cache of immutable segments, so that applications can achieve in-memory performance to the degree that their working sets do fit into memory.
Compute Groups
A compute group is an independent unit of computation, scaling, code deployment, and caching. Every Datomic system has a primary compute group, plus zero or more query groups.
Every compute group comprises one or more compute nodes, and has its own Auto Scaling group and Application Load Balancer. Because databases are immutable, compute group instances require no coordination for query.
Primary Compute Stack
Every running system has a single primary compute stack which provides computational resources and a means to access those resources. A Primary Compute Stack consists of:
- Compute nodes dedicated to transactions, indexing, and caching.
- Route53 and Application Load Balancer (ALB) endpoints
Query Groups
Query groups are valuable if users of your data differ in any of the following ways:
- Application code
- Computational requirements
- Cacheable working sets
- Scaling requirements
A query group is a compute group that:
- Extends the abilities of an existing Datomic system
- Is a deployment target for its own distinct application code
- Has its own clustered nodes
- Manages its own working set cache
- Can elastically auto-scale application reads without any up-front planning or sharding
Query groups deliver the entire semantic model of Datomic. In particular:
- Client code does not know or care whether it is talking to the primary compute group or to a query group
- Query groups are peers with the primary compute group
You can add, modify, or remove query groups at any time. For example, you might initially release a transactional application that uses only a primary compute group. Later, you might decide to split out multiple query groups:
- An autoscaling query group for transactional load
- A fixed query group with one large instance for analytic queries
- A fixed query group with a smaller instance for support
Nodes
Compute groups manage one or more compute nodes. Nodes are EC2 instances that serve ACID transactions , datalog query, and ion applications. Nodes also perform necessary background tasks such as indexing.
Peer Processes
In Datomic Cloud, every compute node is a peer, that is, all nodes have coequal access to the data. A peer process:
- Implements the Datomic Client API
- Transparently caches data
- Queries with memory locality
Ion applications runs in-process with Datomic, and gain all the locality benefits of a peer.
Peer processes are in contrast to a traditional relational database, where servers are closer to the data, and clients are further away.
Caching
Datomic caches improve performance without requiring any action by developers or operators. Datomic's caches:
- Require no configuration
- Are transparent to application code
- Contain segments of index or log, typically a few thousand datoms per segment
- Contain only immutable data
- Are always consistent
- Are for performance only, and have no bearing on transactional guarantees
Datomic's cache hierarchy includes the object cache, EFS cache and optionally Valcache when using i3 instances.
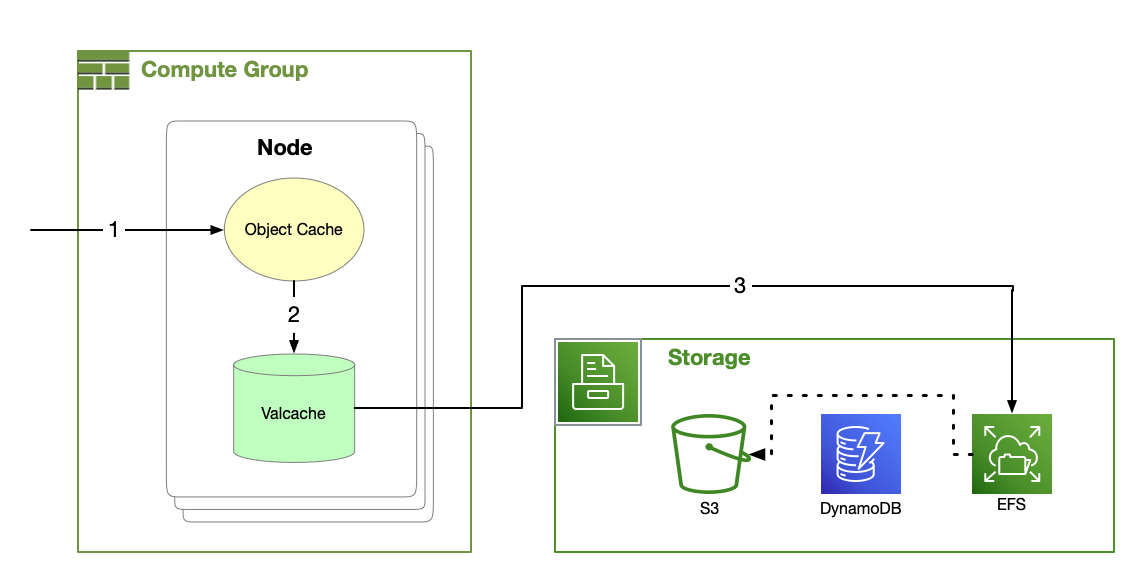
Object Cache
Nodes maintain an LRU cache of segments as Java objects. When a node needs a segment, Datomic looks in the object cache first. If a segment is unavailable in the object cache, Datomic will look next to the Valcache if it's available.
Because each process maintains its own object cache, a process will automatically adjust over time to its workload.
Valcache
Primary Compute Nodes on i3 instance types maintain a Valcache. Valcache implements an immutable subset of the Memcached API and maintains an LRU cache backed by fast local SSDs.
If a segment is unavailable in Valcache, Datomic will look next to the EFS cache.
EFS Cache
The EFS cache contains the entirety of all indexes for all databases. Datomic uses the EFS cache to populate the smaller and faster Valcache and object cache, without the latency of reading from S3.
If a segment is unavailable in the EFS cache, Datomic will load the segment from S3 and repair the EFS cache.
High Availability
Datomic storage and caching are built from components that are automatically distributed and highly available, with no single point of failure.
Datomic compute nodes run in Auto Scaling groups. Compute groups are automatically highly available when they are configured with more than one node.
Applications
Datomic ions provides a complete solution for Clojure application deployment on AWS. In particular, you can:
- Develop and test with real-time feedback at a local REPL
- Deploy to AWS with no downtime
- Expose functions as AWS Lambdas without using the AWS Lambda API
- Expose functions as web services
- Deploy multiple applications that share a common Datomic system
- Elastically scale your entire application instead of many separate elements
- Reproducible deploy across different development stages

Security
Datomic is designed to follow AWS security best practices:
- Datomic client authentication is performed using AWS HMAC, with key transfer via S3, enabling access control governed by IAM roles.
- Data is encrypted at rest using AWS KMS.
- All Datomic compute groups are isolated in a private VPC.
- Datomic is exposed to the internet only via optional AWS API Gateways.
- Datomic EC2 instances run with an IAM role configured for least privilege.
- Datomic requires minimal administration after initial setup. Administrative tasks are performed in CloudFormation, never by logging in to EC2 instances.
API Gateways
An AWS API Gateway acts as a "front door" to your Datomic system, providing traffic management, authorization and access control, throttling, monitoring, and more.
Datomic will automatically configure a VPC Link and API Gateways for internet access to your Datomic system. For each Datomic compute group, you can choose to enable one or both of:
- An API Gateway for Datomic client access
- An API Gateway for your application via HTTP Direct
If your system does not require internet accessibility, you can instead access Datomic from within Datomic's VPC or via VPC peering.
Analytics and SQL
Datomic Cloud supports SQL access for analytics via a connector to Trino. You can treat any set of Datomic attributes as a SQL table, and access your Datomic data from e.g. Python, JDBC, R, and many more.
Datomic analytics works directly against your live system, and does not require coordination or a separate ETL workflow.
Minimal Administration
Datomic automates many operational tasks that must be performed manually in many database systems.
- Datomic is at all times its own complete transactional audit history.
- Datomic automatically creates and manages all needed indexes.
- Because all data is immutable, cache management can be automatic, with no configuration or coordination required. There is no separate cache API, and all database operations benefit from caching automatically.
- Because all processes are peers, developers do not have to worry about data locality for query.
- Datomic durable storage requires no configuration and scales automatically.
- Datomic compute can be scaled manually or automatically, and tasks with different needs can have their own dedicated compute resources.
With ions, Datomic can host your entire application, minimizing the surface area of AWS that you have to manage.
Datomic requires minimal administration after setup. Administrative tasks are performed in CloudFormation, never by logging in to EC2 instances.
Transit
Remote Client API implementations use a wire protocol built on Transit, an open-source data interchange format.